Context
At work, we’ve had a system in production for long enough that now we get the pleasure of building v2-s (or v3-s) of our features.
While continual improvement is exciting, given each v1 feature is in active use, when building v2 features we often end up “changing the wings of the airplane while in flight”.
 Image courtesy of Gemini
Image courtesy of GeminiFor smaller changes, we can handle this with short-lived feature flags, and generally immediately migrating the whole system (and existing production data) to the latest & greatest code/features.
But v2 features are often big enough changes that they are a) time-consuming to roll out, and b) sufficiently different from their v1 data models that clear upgrade paths may not exist for the existing production data.
Our latest Schedules v2 initiative was a particularly acute example of this, and in this post we’ll talk through how we diagnosed and solved the problem, specifically evolving the core Task entity using Single Table Inheritance (STI) with Joist, our in-house ORM.
The Challenge
Without covering too many specifics, our Schedules v2 project involved moving from more static/old-school PERT-based scheduling, to more dynamic, probabilistic-based scheduling (i.e. using Monte Carlo simulations both within and across multiple schedules).
While very cool by itself, with various greenfield features & sub-entities, the revamped schedule feature was also going to cause a lot of churn in our core Task entity, which stores things like which Trade is performing the work, on what date, for what expected duration, etc., as the Task entity is used for:
- Core scheduling features (PERT planning, Gantt charts, assignees, etc.),
- Schedule-adjacent features like task checklists, required sign-off documentation, and trade cost/client revenue information, and
- Miscellaneous data-lake business intelligence reports.
The challenge is that the new scheduling feature replaced ~50% of the “core scheduling” data and relations" of Task with different, probabilistic-based scheduling, but a) kept the other 50% of “core scheduling” data (like basic start/end/durations), as well as b) needed continued integration with many the “schedule-adjacent” features and BI reporting.
…this seems coupled?
A fair ask is “how/why is the Task entity co-mingled with the other schedule-adjacent features?”, but my tldr is that, personally, I generally think that cross-feature domain model cohesion is the primary raison d’etre (reason for being) for custom software systems, because it lets users, and data, stay highly-contextual & interconnected.
Basically they’re all in a single entity graph, which is how the business & end-users of “a single product”, or “a single line of business” want to think of the system; and so we should strive to keep that graph connected as long as possible, i.e. until you hit post-IPO/FAANG-level size of teams/data/entities.
That said, outside the connected domain model, neither the code for our core scheduling algorithms (like PERT’s earliest start/earliest finish) or the new Monte Carlo simulations lives directly in the entities/domain model Task.ts itself, but instead are either utility libraries or, for Monte Carlo sims, a separate stateless microservice dedicated to running the simulations (it turns out JavaScript is not the best language for “run this simulation many times in a tight loop”).
Goals
Back to the Task entity, our goals were to:
Leave existing data/projects using Task v1 largely in-place,
Thankfully both our product team & field ops were onboard with leaving all existing projects on the tasks/schedule v1 feature, as the v1 -> v2 migration for existing data would be painful/extremely expensive/and likely create nonsense/unuseful data anyway. Instead, we’ll just let all existing projects run-out on v1.
Setup only net-new data/projects using Task v2 (when released),
Have the “Task v1” and “Task v2” features know as little about the other as possible, and
Have rest of the system’s
Task-adjacent features be largely agnostic about the v1/v2 dichotomy.
And, of course, minimize both our short-term implementation and long-term maintenance pain.
Auditing Existing Usage
Our first step was to understand how Task was used in the system, to understand the impact of our proposed changes.
Given our system is a monolith, this was actually pretty easy to do: all incoming and outgoing connections (i.e. foreign keys from tasks to other tables, and foreign keys from other tables to tasks) to Task are listed in Joist’s TaskOpts type, which a small sample looks like:
export interface TaskOpts {
// All primitive columns & enums...
durationInDays: number;
startDate: Date;
isStartNode?: boolean | null;
baselineStartDate?: Date | null;
internalNote?: string | null;
// Also any "outgoing" FKs to other parts of the system
internalUser?: InternalUser | InternalUserId | null;
tradePartner?: TradePartner | TradePartnerId | null;
invoice?: Invoice | null;
// Also well as any "incoming" FKs that depend on task
billLineItems?: BillLineItem[];
homeownerContractDraws?: HomeownerContractDraw[];
requiredTaskDocuments?: RequiredTaskDocument[];
documents?: Document[];
jobLogNotes?: JobLogNote[];
}
Joist also produces a “reactivity report” (that we’ve not technically open-sourced yet) that further shows how Task is connected to the rest of the domain model, beyond the immediate foreign keys, via Joist’s reactive rules & reactive fields features:
Task will trigger reactions in:
HomeownerNote
[homeownerVisible] -> homeownerNotes HomeownerNote.ts:127
RequiredTaskDocument
[documents] -> requiredTaskDocuments RequiredTaskDocument.ts:8
ScheduleSubPhase
[scheduleSubPhase,endDate,globalTask] -> scheduleSubPhase targetEndDate
Somewhat surprisingly, Task did not have a meaningful amount of reactivity, which was actually good news for our purposes!
So, just looking at TaskOpts, in total we had:
- 23 columns
- 7 outgoing relations
- 17 incoming relations
Which in total was about 50 fields/relations to consider. We then made notes on each of “what is staying vs. being deprecated”, i.e.:
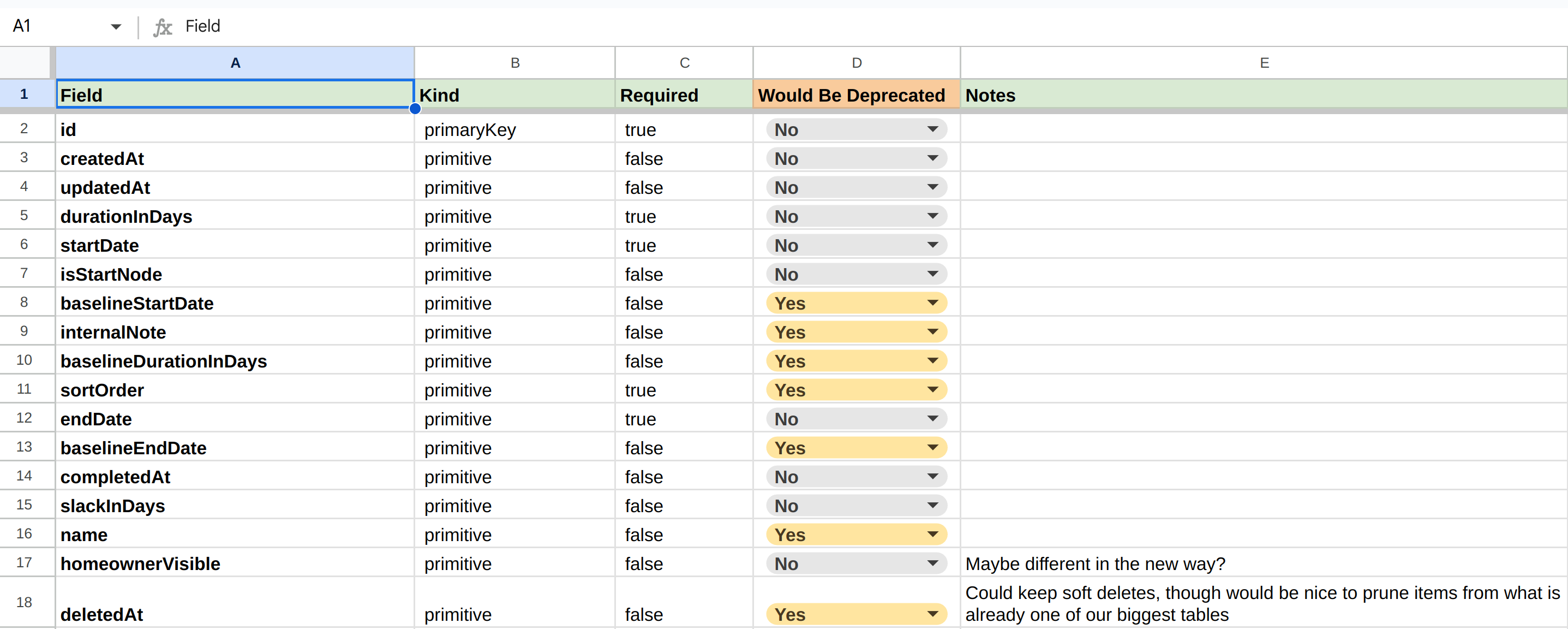 Audit of our Task relations
Audit of our Task relationsThis audit was great because it gave us context & concrete data points for then evaluating our high-level approaches, instead of just our initial gut feelings.
High Level Approaches
We generally had three approaches to consider:
- Create an entirely new table/entity, like
tasks_v2/TasksV2, or - Reuse the existing
tasks/Tasktable/entity, and somehow manage the v1/v2 differentiation - Split the new entity/feature out into an entirely new service/its own domain model
The 3rd option was both too expensive to tackle immediately, and also lacked consensus on being the best long-term approach (per my prior preference of keeping a unified entity graph as long as possible), so we focused on the first two approaches: how to evolve the Task entity within our current domain model.
Approach 1. Create a new TaskV2 Entity
In this approach, we’d create a new tasks_v2 / TaskV2 entity, totally separate from the existing tasks table, which would have a clean-slate implementation (brand new rows, columns, etc.).
Pro: Clean slate for the new Task v2 feature
The new table/entity would have only the fields/relations the new feature needs, and not deal with any legacy fields or integrations.
This is the best for Task v2 feature itself, because there would be no legacy “if Task v1 / else Task v2” code immediately within the v2 scheduling system.
Con: All non-deprecated Task v1 & Task-adjacent features need to re-integrate with Task v2
Basically the opposite of the ‘Pro’, all other features would need to have “if Task v1 / else Task v2” handling in their code.
At first, we liked the clean-break of creating a new entity, as did our product team, as to their eyes this was an entirely new scheduling system.
However, the goal of the Task v2 project was not solely to implement “just the new scheduling features” in isolation, but to also ensure the continuity of how Task integrates with the rest of the system.
Per the above audit, as we dug into the TaskOpts & started realizing how many other features would need to be taught about “the new task” entity, in a way that would add trivial-but-tedious boilerplate to their integration without any change/upside to their specific integration, we started doubting this option.
Approach 2. Reuse the existing Task Entity
In this approach, we keep a single Task entity, which basically flips the pros & cons compared to the prior approach:
Pro: Existing
Task-adjacent features can stay largely untouchedPro: We don’t really want to introduce “a new task” concept to the domain model.
In thinking of our system using Ubiquitous Language, i.e. the domain model as a conceptual mapping of the business domain, we were not actually introducing a new concept, a new entity, to the domain.
Even though the v2 tasks will have more/different functionality, and “seem very different” to the implementation itself, no user in the field would speak of “v1 tasks” vs. “v2 tasks” as if they were actually separate, real-world concepts.
Con: Unclear how to manage the v1/v2 differentiation within the schedule/
TaskitselfI.e. we’re basically choosing whose life to make easier: the new Task v2 feature, or the entire rest of the system.
Given these two pros, that there is a single Task concept that both users and the majority of existing Task-adjacent code would like to keep using, without “which Task entity do I care about?” complications, we changed our mind and started digging into the easiest way to make Approach 2 work.
Tactical Implementation Options
Within Approach 2 itself (reusing the Task entity), there were also several tactical options:
Add adhoc
if v1/else v2handling to each v1-/v2-specific location withinTask.ts& ourTask-related GraphQL resolvers.In this approach, we’d add the v2-specific columns to the
taskstable, deprecate the v1-specific columns in thetaskstable, and then just generally add “if v1/v2” checks at random spots in the codebase. Liketasks.old_columnis required for v1 tasks,tasks.new_columnis required for v2 tasks.The “if v1/v2” checks would also be necessary in our domain validation rules (i.e. required rules and other business invariants), lifecycle hooks (i.e. on soft-delete, perform some side effect), and Joist reactive fields.
This is doable, but it doesn’t create any fundamental code-level differentiation between v1 & v2 tasks, and instead just scatters the differences randomly in the codebase.
- Pro: Doesn’t break any existing data/Looker reports that use
tasks - Con: Requires making task v1/v2-specific columns nullable (shared table)
- Con: No code-level differentiation between v1 & v2 tasks
- Pro: Doesn’t break any existing data/Looker reports that use
Use Class Table Inheritance to model
TaskV1andTaskV2as subtypes ofTask, with a sharedtasks“base table” and separatetasks_v1andtasks_v2sub-tables.We like judiciously using CTI, because it has very clean modeling of “this entity has polymorphic subtypes” within both the database schema and the domain model. For example, it lets each subtype have strong database-level constraints and subtype-specific FKs (both outgoing & incoming); (the Joist STI documentation goes more into these details).
However, needing to move the v1 columns into a
tasks_v1table (to satisfy CTI’s table-per-subtype) would defeat the goal of minimizing outside observability of the change (particularly to the data lake), and also we don’t really want “TaskV1” and “TaskV2” concepts in our domain model, which is what CTI is best suited for. We’re looking for more of an implementation hack.- Pro: Code-level differentiation between
TaskV1andTaskV2subtypes - Pro: Allows keeping task v1/v2-specific columns not-nullable (dedicated CTI sub-tables)
- Con: Breaks existing data/Looker reports that use
tasks(task v1 columns move totasks_v1sub-table)
- Pro: Code-level differentiation between
Use Single Table Inheritance to model
TaskV1andTaskV2as subtypes ofTask, but all in a single sharedtaskstable.While CTI is a purer approach to modeling polymorphic subtypes, STI is a more pragmatic approach that allows for a shared table, and so doesn’t break existing data/Looker reports that use
tasks.- Pro: Code-level differentiation between
TaskV1andTaskV2subtypes - Pro: Doesn’t break existing data/Looker reports that use
tasks - Con: Requires making task v1/v2-specific columns nullable
- Pro: Code-level differentiation between
Because of the pros/cons discussed above, we’ve historically preferred using CTI in our domain model, but for this project decided that STI to be the best approach.
Adding STI Support to Joist
One wrinkle was that Joist did not support STI when we were evaluating approaches.
This introduced some initial risk, but thankfully it was a proverbial “hack day of effort” to add support for STI. This was primarily because Joist already had CTI support, which is generally the harder of the two models to implement, so adding STI was a relatively minor effort.
While building the STI support in Joist, we implemented a few features to make it “more CTI-ish”:
Domain-level enforcement of not null subtype columns
To mitigate the lack of
NOT NULLconstraints in the database itself (for subtype-specific columns), we added astiNotNull: truesetting injoist-config.json, for Joist to add a domain-level validation rule to enforce non-null values, as well as mark the field as required / non-optional in the type system.(Ideally we can also enforce this
NOT NULLvalidation with a conditionalCHECKconstraint in the database, and teach Joist to infer thestiNotNull-ness by recognizing the check constraint at codegen time, but that’s a future improvement.)Tagging of FKs for “v1” or “v2” tasks
When an incoming foreign key points to the
taskstable, i.e. something liketrade_payment.task_id, it can be useful to know whether the FK was meant to point at “any task” or a specific v1/v2 subtype (which, per above, is a “pro” of CTI that STI lacks).I.e. usually FKs that are implementation details of the v1 feature should point to “only v1 tasks rows”, while implementation details of the v2 feature should only to “only v2 tasks rows”.
To mitigate this, we added support for tagging incoming foreign keys with
stiType: "TaskV1" | "TaskV2"injoist-config.json, which Joist will then use to: a) validate the FK value is the correct type at runtime, and b) use the respectiveTaskV1/TaskV2type in the type system.Concretely in our
TradePayment.taskexample, it meant thatTradePayment.taskwas typed asTaskV1and could only be read/written by code that knew it was coupled toTaskV1functionality.(This is probably not something we can enforce at the database level, because there isn’t a way to distinguish between v1 & v2 ids from the referencing side of the FK, so the
joist-config.jsonhint will be good enough.)
Both of these features made the STI-based Task base types and subtypes much more “CTI-ish” in terms of developer ergonomics, which was a big win.
Choosing Good Long-Term Names
While I’ve used TaskV1 and TaskV2 as the “v1” and “v2” subtype names in this post, having “v1” and “v2” in entity names is admittedly kind of gross, so we brainstormed some alternative names and ended up:
ScheduleTaskas the “v1” task name, which worked well because the previous system was very “schedule-centric”, andPlanTaskas the “v2” task name, as the new system is more “probabilistic planning-centric”.
These names were admittedly somewhat arbitrary, given they’re just slightly different ways of saying “task”, but we liked the idea that, a year from now when we’ve aged the ScheduleTask / v1 feature entirely out of the system (fingers crossed!), we’ll be left with a good/proper name for PlanTask.
Implementation Steps
With the high-level approach (evolving the Task entity) and tactical implementation (STI) chosen, we took the following implementation steps:
- Push nearly all columns/relations from
Taskdown intoTaskV1 - Start implementing new features in
TaskV2 - Eventually pull shared functionality from
TaskV1back “up” intoTask
Particularly step 1, “push all columns/relations down into TaskV1” was not our initial approach; we’d assumed that, from the get to, we’d keep all the “to be shared” functionality in the base Task table.
However, after some prototyping, it became apparent that, due to the amount of code changes involved, the lowest-risk approach was actually to “clean cut” the entire system over to “always blithely create (old) TaskV1 and assume TaskV1 is the ‘only task’ in the system”. This involved tedious but extremely routine changes like “call em.create(TaskV1) instead of em.create(Task)”.
This let us get over the biggest hurdle of “there are two tasks (…but really the whole codebase just uses the first one…)” merged into production in the shortest amount of time, basically a week.
Compared to other “feature v2” migrations we’ve done in the past, which have had long-lived feature branches (something we rarely do), this immediate merge was a big relief.
Once this initial, big Step 1 was complete, the rest of the changes became smaller and more routine:
- Step 2 was using the
TaskV2“clean-ish slate” (that doesn’t have any of theTaskV1relations on it, but is “still aTask”) to built out the new scheduling domain model, and - Step 3 was, while doing Step 2, nudge some of the
TaskV1relations down intoTaskas needed.
Both of these steps could be performed incrementally & iteratively, on a relation-by-relation basis, as the schedules project progresses.
Which meant we’d achieved the goal of unblocking the engineering squad to deliver the new feature, without having to rebuild all the historical integrations.
At time of this writing, the project is still early, but the first major stage (teaching the system about the two STI subtypes without completely breaking/rewriting everything) is complete, and we’re cautiously optimistic about the rest.
Conclusion
Wrapping up, this was probably the longest post I’ve written in awhile, but we covered how we took what is the blessing & curse of every software developer: “a new feature! …that also must integrate with the existing features” and so going through a process of:
- Evaluating whether create-new or evolve-existing domain entities
- Look at number of usages; if there’s more than a handful, probably evolve
- Consider whether this is really a new domain concept, or just an evolution of an existing one
- Evaluating whether to use STI or CTI for “v1/v2” entity evolution
- CTI is more pure, but STI can be more pragmatic
- CTI is better for new domain concepts, STI is better for evolving implementations
Acknowledgments
Many thanks to Ben Lambillotte and Zach Gavin, who were instrumental in researching, evaluating, and prototyping the “new or evolve?” approaches & trade-offs, and Ben in particular for doing basically all the “take theory to practice” work in rolling these changes out to the system.