We recently tackled a problem at Bizo where we wanted to decouple our high-volume servers from our MySQL database.
While considering different options (NoSQL vs. MySQL, etc.), in retrospect we ended up implementing a SOA-version of the Command Query Separation pattern (or Command Query Responsibility Segregation, which is services/messaging-specific).
Briefly, in our new approach, queries (reads) use an in-memory cache that is bulk loaded and periodically reloaded from a snapshot of the data stored as JSON in S3. Commands (writes) are HTTP calls to a remote JSON API service. MySQL is still the authoritative database, we just added a layer of decoupling for both reads and writes.
This meant our high-volume servers now have:
- No reliance on MySQL availability or schema
- No wire calls blocking the request thread (except a few special requests)
The rest of this post explains our context and elaborates on the approach.
Prior Approach: Cached JPA Calls
For context, our high-volume servers rely on configuration data that is stored in a MySQL database. Of course, the configuration data that doesn’t have to be absolutely fresh, so we’d already been using caching to avoid constantly pounding the database for data that rarely changes.
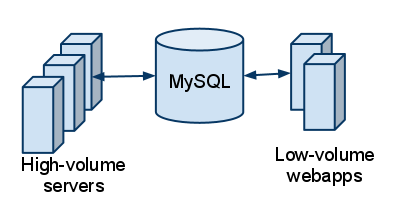
There were several things we liked about this approach:
We use Amazon RDS for the MySQL instance, which provides out-of-the-box backups, master/slave configuration, etc., and is generally a pleasure to use. We enjoy not running our own database servers.
We also have several low-volume internal and customer-facing web applications that maintain the same data and are perfectly happy talking to a SQL database. They are normal, chatty CRUD applications for which the tool support and ACID-sanity of a SQL database make life a lot easier.
That being said, we wanted to tweak a few things:
Reduce the high-volume servers’ reliance on MySQL for seeding their cache.
Although RDS is great, and definitely more stable than our own self-maintained instances would be, there are nonetheless limits on its capacity. Especially if one of our other application misbehaves (which has never happened…cough), it can degrade the MySQL instance to the point of negatively affecting the high-volume servers.
Reduce cache misses that block the request thread.
Previously, configuration data (keyed by a pre-request configuration id) was not pulled into cache until it was needed. The first request (after every cache flush) would reload the data for it’s configuration id from MySQL and repopulate the cache.
While not initially a big deal, as Bizo has grown, we’re now running in multiple AWS regions, and cache misses require a cross-region JDBC call to fetch their data from the MySQL server running in us-east.
Illustrated in code, our approach had, very simplified, been:
class TheServlet {
public void doGet() {
int configId = request.getParameter("configId");
Config config = configService.getConfig(configId);
// continue processing with config settings
}
}
class ConfigService {
// actually thread-safe/ehcache-managed, flushed every 30m
Map<Integer, Config> cached = new HashMap<Integer, Config>();
public Config getConfig(int configId) {
Config config = cached.get(configId);
if (config == null) {
// hit mysql for the data, blocks the request thread
config = configJpaRepository.find(configId);
// cache it
cached.put(configId, config);
}
return config;
}
}
Potential “Big Data” Approaches
Given our primary concern was MySQL being a single point of failure, we considered moving to a new database platform, e.g. SimpleDB, Cassandra, or the like, all of which can scale out across machines.
Of course, RDS’s master/slave MySQL setup already reduces its risk of single machine point of failure, but the RDS master/slave cluster as a whole is still, using the term loosely, a “single point”. Granted, with this very loose definition, there will always be some “point” you rely on–we just wanted one that we felt more comfortable with than MySQL.
Anyway, for NoSQL options, we couldn’t get over the cons of:
Having to run our own clusters (except for SimpleDB).
Having to migrate our low-volume CRUD webapps over to the new, potentially slow (SimpleDB), potentially eventually-consistent (Cassandra) NoSQL back-end.
Still having cache misses result in request threads blocking on wire calls.
Because of these cons, we did not put a lot of effort into researching NoSQL approaches for this problem–we felt it was fairly apparent they weren’t necessary.
Realization: MySQL is Fine, Fix the Cache
Of course, we really didn’t have a Big Data problem (well, we do have a lot of those, but not for this problem).
We just had a cache seeding problem. Specifically:
All of our configuration data can fit in RAM, so we should be able to bulk-load all of it at once–no more expensive, blocking wire calls on cache misses (basically there are no cache misses anymore).
We can load the data from a more reliable, non-authoritative, non-MySQL data store–e.g. an S3 snapshot (
config.json.gz) of the configuration data.The S3 file then basically becomes our alternative “query” database in the CQRS pattern.
When these are put together, a solution emerges where we can have a in-memory, always-populated cache of the configuration data that is refreshed by a background thread and results in request threads never blocking.
In code, this looks like:
class TheServlet {
public void doGet() {
// note: no changes from before, which made migrating easy
int configId = request.getParameter("configId");
Config config = configService.getConfig(configId);
// continue processing with config settings
}
}
class ConfigService {
// the current cache of all of the config data
AtomicReference<Map> cached = new AtomicReference();
public void init() {
// use java.util.Timer to refresh the cache
// on a background thread
new Timer(true).schedule(new TimerTask() {
public void run() {
Map newCache = reloadFromS3("bucket/config.json.gz");
cached.set(newCache);
}
}, 0, TimeUnit.MINUTES.toMillis(30));
}
public Config getConfig(int configId) {
// now always return whatever is in the cache--if a
// configId isn't present, that means it was not in
// the last S3 file and is treated the same as it
// not being in the MySQL database previously
Map currentCache = cached.get();
if (currentCache == null) {
return null; // data hasn't been loaded yet
} else {
return currentCache.get(configId);
}
}
private Map reloadFromS3(String path) {
// uses AWS SDK to load the data from S3
// and Jackson to deserialize it to a map
}
}
A Few Wrinkles: Real-Time Reads and Writes
So far I’ve only talked about the cached query/reads side of the new approach. We also had two more requirements:
Very (very) infrequently, a high-volume server will need real-time configuration data to handle a special request.
The high-volume servers occasionally write configuration/usage stats back to the MySQL database.
While we could have continued using a MySQL/JDBC connection for these few requests, this also provided the opportunity to build a JSON API in front of the MySQL database. This was desirable for two main reasons:
It decoupled our high-volume services from our MySQL schema. By still honoring the JSON API, we could upgrade the MySQL schema and the JSON API server at the same time with a much smaller, much less complicated downtime window than with the high-volume services talking directly to the MySQL schema.
The MySQL instance is no longer being accessed across AWS regions, so can have much tighter firewall rules, which only allow the JSON API server (that is within its same us-east region) access it.
The new setup looks basically like:
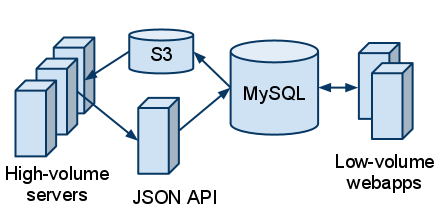
Scalatra Servlet Example
With Jackson and Scalatra, the JSON API server was trivial to build, especially since it could reuse the same JSON DTO objects that are also serialized in the config.json.gz file in S3.
As an example for how simple Jackson and Scalatra made writing the JSON API, here is the code for serving real-time request requests:
class JsonApiService extends ScalatraServlet {
get("/getConfig") {
// config is the domain object fresh from MySQL
val config = configRepo.find(params("configId").toLong)
// configDto is just the data we want to serialize
val configDto = ConfigMapper.toDto(configDto)
// jackson magic to make json
val json = jackson.writeValueAsString(configDto)
json
}
}
Background Writes
The final optimization was realizing that, when the high-volume servers have requests that trigger stats to be written to MySQL, for our requirements, these writes aren’t critical.
This means there is no need to perform them on the request-serving thread. Instead, we can push the writes onto a queue and have it fulfilled by a background thread.
This generally looks like:
class ConfigWriteService {
// create a background thread pool of (for now) size 1
private ExecutorService executor = new ThreadPoolExector(...);
// called by the request thread, won't block
public void writeUsage(int configId, int usage) {
offer("https://json-api-service/writeUsage?configId=" +
configId +
"&usage=" +
usage);
}
}
private void offer(String url) {
try {
executor.submit(new BackgroundWrite(url));
} catch (RejectedExecutionException ree) {
// queue full, writes aren't critical, so ignore
}
}
private static class BackgroundWrite implements Runnable {
private String url;
private BackgroundWrite(String url) {
this.url = url;
}
public void run() {
// make call using commons-http to url
}
}
}
tl;dr We Implemented Command Query Responsibility Segregation
With changing only a minimal amount of code in our high-volume servers, we were able to:
Have queries (most reads) use cached, always-loaded data is that periodically reloaded from data snapshots in S3 (a more reliable source than MySQL)
Have commands (writes) sent from a background-thread to a JSON API that saves the data to MySQL and hides JDBC schema changes.
For this configuration data, and our current requirements, MySQL, augmented with a more aggressive, Command Query Separation-style caching schema, has and continues to work well.
For more reading on CQS/CQRS, I suggest:
Both the Wikipedia article and Martin Fowler’s CommandQuerySeparation, however they focus on CQS as applied to OO, e.g. side-effect free vs. mutating method calls.
For CQS applied to services, e.g. CQRS, Udi Dahan seems to be one of the first advocates of the term. Since then, CQRS even seems to have its own site and google group.
(Note: this post was also cross-posted on the Bizo dev blog. If you’re interested in more posts on AWS/Java/Scala problems, you should check it out.)