React’s Virtual DOM approach has “won” the current generation of web framework architectures.
For the purposes of this article, I’ll assume you’re familiar with the approach, given it’s popularity and variety of articles on the topic.
What I’ll describe is how we applied the Virtual DOM pattern to a systems integration project at Bizo, between our Marketing Automation Platform and several of our vendors, specifically the AppNexus and LinkedIn ads APIs.
Credit to Mark Dietz
First off, the architecture I’m describing here was, within our system, solely conceived, prototyped, and rolled out by Mark Dietz.
I had written the original version of our integrations, which I’ll describe the previous approach below, and after awhile (and an annoying bug or cough three), Mark took a step back, saw how we could separate the concerns, pitched the approach, and then implemented it.
I talked with Mark before writing this post up, and neither of us can remember for sure whether he was directly inspired by React.
Mark prefers to avoid most UI programming, but I would have been aware of/chatting about the React Virtual DOM approach in the ~2015 timeframe when he implemented this, so it is likely there was some cross-pollination of ideas.
The core approach of “generate an ideal/immutable state, and then diff current vs. ideal” does seem pretty generic, e.g. I remember thinking of parallels to git DAGs/diffs, and surely there is a lot of prior art.
But, anyway, how much Mark was inspired by React itself is less important than: a) Mark drove all of this on our side, and b) in retrospect, it is actually eerily similar to the Virtual DOM, as I’ll shut up and get to describing.
Decoupling from 3rd Party Vendors
For context, the problem we were working on was a pretty standard “our system syncs to-/from vendor X’s system”.
Specifically, we had a web application, and our web application was 100% isolated from the backend vendors.
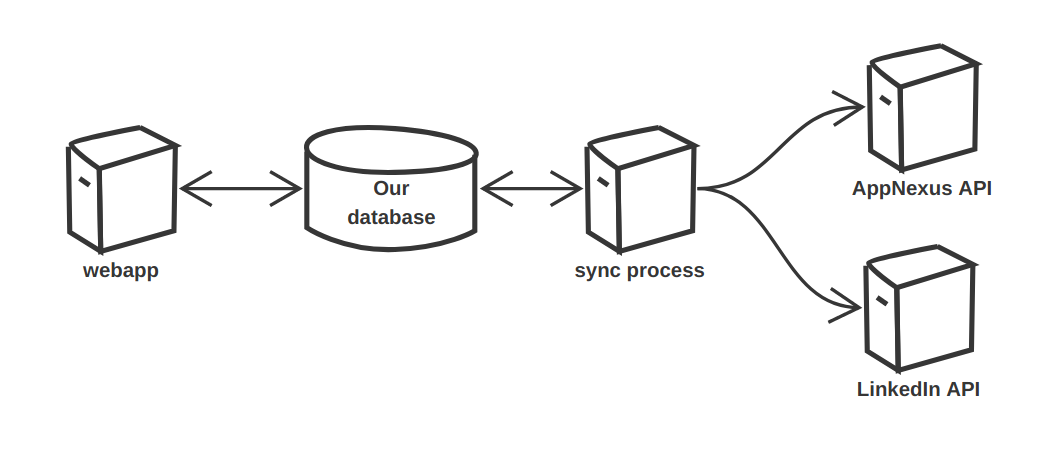
There were two primary reasons for this:
-
Our webapp was isolated from production issues in the vendor APIs.
For example, if the AppNexus or LinkedIn APIs: accidentally revoked our API keys (happened), accidentally let an SSL certificate expire (happened), released new code that either introduced actual bugs or subtle semantic changes that broke us (happened happened), our webapp/front-end users would be blithely aware, while we got alerts and fixed the issue behind the scenes.
Granted, it would be naive to assert we’d have better up-time than top-tier vendors like LinkedIn and AppNexus, but it is not really “we’d have better up time”, it’s just more about having control/isolation when issues do happen.
-
Our webapp and database can be written solely in our business’s domain language.
For example, a feature of the Bizo system was “Nurture Flow” entities. These were a drip-esque view of display/RT campaigns which were somewhat novel to the advertising ecosystem.
So, the vendor APIs, LinkedIn and AppNexus, did not have a concept of “Nurture Flow”, we had to map our domain concepts to their concepts, which were more traditional advertising campaigns and creatives.
Which is just fine, but we didn’t want to leak this implementation detail of “a Nurture Flow looks like X in AppNexus and looks like Y in LinkedIn” throughout our entire webapp and various internal systems.
Instead, this architecture let the majority of our systems be blithely unaware of what was necessary to represent our domain in vendor systems, and instead could just speak our native language.
Granted, there are downsides of this architecture:
-
We need to keep a copy of any vendor data that we want to show a user in our own system.
The common offender here is analytics from the vendors’ systems, which for us was advertising stats, which we would periodically download and store locally.
This adds some delay to getting stats, although advertising stats at the time were typically not super real-time anyway. And, in theory, if your vendor supports real-time data feeds, you should be able to fairly easy pull that to their own internal real-time streams/infrastructure.
-
It can also be questionable to keep a local copy of all things if your vendor has dramatically more/better data than is worth pulling over. E.g. for analytics, either systems that are extremely fast to query, or lots of data to query, that is just a challenge to replicate (or not worth the ROI to replicate) internally.
In this case, having an escape hatch that directly queried and transformed the vendor’s API in real-time would be just fine, and could live along side this approach, but is not something we needed at the time.
First Approach: Interleaved Mapping and Sync
The first version of our sync processes was a pretty straight forward series of for loops:
val nfIds = findNurtureFlowsMarkedDirty()
nfIds.foreach { nfId ->
val nf = loadNf(nfId);
// each step has a campaign, so drill into those
nf.steps.foreach { step ->
val campaign = appNexus.findCampaign(nf.id + "_step1")
if (campaign == null) // make a new one
// map attributes as needed
campaign.name = step.name
// ...other attributes...
// now create/update
appNexus.saveCampaign(campaign)
// each step has creatives, so drill into those
step.creatives.foreach { creative ->
// same basic process
}
}
}Things were more abstracted than this, but that is the basic gist.
This worked, but there were a few downsides:
-
We made a lot of API calls that were potentially not necessary.
E.g. if a nurture flow created ~20 AppNexus entities (I’m somewhat making this up, as I don’t remember exactly), and each sync we’d re-look up each AN entity and re-save it.
As with most vendor APIs, we had API limits to stay under, and our “constantly read and write all the things” approach would lead to our AppNexus API cient purposefully self-throttling our sync process to stay under that limit.
This slowed down our sync process and meant changes users made to our system took longer to be reflected in the backend/vendor systems.
-
The concerns of “mapping from our entities to their entities” and “persisting their entities” is interleaved when they are actually fairly different problems.
Using Codes for Idempotency
As a quick tangent, if you’re building a vendor API, I have a request that makes my life as an integrator much easier: add code fields to all of your entities.
What is a code? It’s a client-provided unique identifier for a vendor entity.
(I admit this is not really an industry-wide term, but it is what AppNexus called it, and I’ve not seen alternative terms provided, so I’m running with that.)
E.g. the vendor system will have it’s own internal primary identifiers, derived from it’s internal storage or UUIDs or what not. But the code is our unique identifier for a given vendor identity.
Having codes lets me easily achieve idempotency in my sync process, as the combination of client-provided (assuming I deterministically derive the code for each entity I want in the vendor system) + vendor-enforced unique constraints means I can avoid worst-case scenarios like this:
- Our user saves “nurture flow id #1”
- Our sync process runs, creates an AppNexus Campaign, it gets vendor id 1234
- For some reason, our sync process blows up, and we’re not able to record “we created campaign w/vendor id 1234”
- Our sync process reruns, creates another AppNexus Campaign, it gets vendor id 2345
- For some reason, our sync process again blows up…
- Repeat until we have 100s of duplicate campaigns in AppNexus for what is essentially one campaign on our side
- Now let’s say each of these campaigns had a separate $100/day budget, and they all start spending money in parallel
Without idempotency, we have a big problem.
(You could alternatively assert we should not do automatic retries, but then you have to baby sit your sync process and constantly, manually investigate every likely-transient blip.)
The solution to this, which is very standard/not novel, is to make our sync process idempotent, and to check if the vendor entity “for this nurture flow” already exists before creating a new one.
The problem then is how do we find a vendor entity that is “for this nurture flow”? We need to do a query, but on what?
If there is a Campaign name field, we could use that, e.g. set the campaign name to something unique and 100% deterministic, e.g. “nf #1 step #2” (where the “#1” and “#2” are our internal ids, so this name is deterministic) on creation, and then do a search on “does campaign with name ‘nf #1 step #2’ already exist?” before creating each new campaign.
Using a name attribute has some pros/cons:
- Given this is a vendor API, the
namevalue is probably not visible to your end user, but it might be visible to internal staff, so it’d be nice to put a real name in there instead of a bunch of ids/guids. - Many entities don’t have
namefields, so then you have to hope there is a unique, write-once field(s) that uniquely identities what “vendor entity X” maps to in your “local entity Y”. - The vendor system may/may not enforce unique names, which granted we can still up-front query for “does this name exist?” to achieve read-before-every-write idempotency, but having enforced unique constraints is always a nice warm fuzzy.
So, that would work, but the easiest, more general solution solution I’ve seen is for all vendor entities to have a code field which is, as discussed:
- used solely for client (our) identification purposes and has no meaning to the vendor system itself, and
- enforced to be unique (within our view of the vendor’s world, e.g. if the vendor has two clients, those clients should have separate code namespaces).
Big kudos to AppNexus, whose API exposed me to this pattern (I had solved similar “sync process must be idempotent” things before, but without the luxury of first-class codes in the API).
We never had a “100 vendor campaigns accidentally created a single local campaign” bug with AppNexus, due do these codes. Unfortunately, we did have a bug like this for LinkedIn, whose API does not support codes, but thankfully we caught it pretty early and handled it with more verbose idempotency checks.
Second Approach: Diff and Sync
Finally, the pay off, which by now is perhaps obvious: Mark’s refactoring split our sync process into two phases:
- Build an ideal graph of what the vendor entities should look like,
- Diff this ideal graph against reality and only send diffs
Code wise, it’s conceptually very simple:
val nfIds = findNurtureFlowsMarkedDirty()
nfIds.foreach { nfId ->
val nf = loadNf(nfId);
val anDesired = mapToAppNexus(nf)
val anCurrent = loadCurrentAn()
val diff = diff(anDesired, anCurrent)
diff.changes.foreach { c ->
c.apply(appNexusClient)
}
}The upshot of this is that mapToAppNexus becomes much simpler: exactly like React components, which do a “dumb”, one-way rendering of their internal state to the ideal DOM state, our mapToAppNexus can create an ideal, one-way mapping from our internal domain model’s state to the ideal vendor state.
Then we move the “oh right, make actual wire calls” work all to the diff + apply section.
Which, just like React’s optimization/reconciliation of “only write to the DOM when necessary” (because that is expensive), means we’ve also gained the optimization of “only write to the vendor API when necessary” (which is similarly expensive).
Granted, a downside of this approach is that we have to write the generic diff + apply methods, which might be slightly tricky (yet again similar to React’s DOM reconciliation, which I assume is non-trivial).
However, ideally our diff + apply logic can be written just once, generically, and then reused/amortized across the many entities in our system that use it. Just like how React’s DOM reconciliation is reused/amortized across every React application, which doesn’t have to resolve/rewrite the DOM diff + apply logic.
Nuances of Diffing
We found two nuances of diffing that are worth highlighting:
-
Being able to differentiate between creates (new entities) and updates (existing entities).
This goes back to the previous point about codes: ideally you can leverage codes, in that your ideal “rendered” graph of vendor entities should each have their own unique codes, and then you can resolve those codes to “does this code already exist or not in the vendor API”?
Relating to React yet again, this is exactly like React using the
keyattribute to detect “does this element already exist in the DOM?”If you cannot use codes, I think diffing is still doable (and you have to do idempotency checking somehow anyway), but it will be more tedious.
-
Tracking the resolution of “logical identity” (i.e. the code) to “physical identity” (i.e. the vendor’s actual entity id).
This piggybacks on the 1st, but basically if I create a graph like:
* campaign code=1 * creative code=2, parent=campaign * budget code=3, parent=creativeThe Creative and Budget entities (they are probably DTOs in your graph) likely have pointers to the parent campaign, but when the Creative/Budget is put on the wire, it will need the physical id of the vendor campaign.
The solution here is again codes, as you can maintain a map of “vendor campaign w/code 1 is vendor id 456”, and then add-in the physical vendor id (for either an update or a reference from one vendor entity to another) before the update goes on the wire.
If I was writing this section ~2-3 years ago, I’d probably have included snippets of code for these two problems, but I no longer have that code, and also in retrospect neither is that hard, and also closely tied to what your “ideal graph” of vendor entities looks like, e.g. what DTOs/etc. you’re using to represent them.
We had re-used the same DTOs that our client library put on the wire for JSON/API calls, which worked well, as then the apply logic could drop the “yep, this has changes” vendor DTO directly onto the wire without any mapping.
Leveraging a Vendor Cache
One of the upshots of Mark’s refactoring is that it isolated the “find existing vendor entities” into a single place, so we could more easily refactor it.
In particular, we moved it away from the original approach of “always make a wire call to look up existing vendor entities” (which was required for our idempotency checks) to “use a local cache of vendor entities”.
This dramatically reduced the wire calls we were making to AppNexus, and so not only sped up our sync process, but more importantly gave us some much-needed relief on our AppNexus API limits (we’d been bumping into them, and regularly negotiating with AppNexus support to have them increased).
In our case, our “cache” was a serialized list of JSON objects that we’d retrieve from the AppNexus API and then store in Amazon S3, e.g. all vendor entities X existed in an s3://.../X.json file that we would periodically update.
Granted, having an out-of-date cache, and so incorrectly missing/applying diffs, is also a bad thing, so after downloading the last S3 JSON snapshot, we would also run a local “update the cache to as most recent as possible”.
We were able to do this because the AppNexus’s API supported “fetch any entities that have changed since timestamp X” for each of their entities.
This was great because our system was not the sole writer to AppNexus, e.g. AppNexus could make their own internal changes (reject a creative, turn off a campaign, etc.,), as well as our own adops people could directly login and hand-edit entities if needed.
With this “have changed since” capability, it was pretty easy (but also not without bugs/nuances) to:
- Download the snapshot
campaigns.jsonfile from S3 with ~1000s of campaigns - Within the
campaigns.jsonfile, pull out the “max/last seenchanged_attimestamp” from when the snapshot was made - Query AppNexus for any campaigns changed since our max/last-seen
changed_at - Store those ~handful of updated campaigns in our local cache
- Run the sync process, now with a “really really close to current” local cache
Tangentially, a bug/nuance it took us awhile to figure out is that we had to query by changed_at >= X and order by changed_at. The reason is that, without this order by changed_at, the default ordering was by id, and if we started fetching ~10 pages of results, then on the 5th page, a new entity (with a low id) was changed that on a page we’d already “seen”, our paging would get bumped off by one, and we’d miss that update. Ordering by changed_at kept any new updates that happened while we’re paging to be added to the end of our existing paging/cursor.
That bug aside, this vendor cache approach ended up being very robust, and dramatically sped up our sync time and, even better, dramatically lowered our AppNexus API calls.
Summary of Vendor Requests
This is a long post, but as a summary of my requests to those building vendor APIs:
-
Please add a
code(client-provided unique id) field to all of your entities.Per previously, this will help me from creating tons of duplicate entities during retry/failure scenarios.
-
Please add a “find all entities changed since timestamp” query for each of your entities.
Again per previously, this will help me to, if needed, create a local cache of entities, and keep it up-to-date without constantly re-fetching every single entity.
This can both make my processes much faster and, even better for you, reduce the QPS load I make on your systems from constantly doing unnecessary reads.
Ironically, I started this post with “here’s a system that we implemented for both of our vendors, AppNexus and LinkedIn …”.
That is not true, we only implemented this for AppNexus, and it would have been more difficult for us to implement against the LinkedIn API, precisely because it lacked both of these features.
Obviously we had to handle idempotency somehow, and so we did, but without codes it was a very adhoc process, so something that would be hard to generalize into a diff + apply reconciliation algorithm.
And without the “query for entities changed since”, we’d not be able to leverage a local cache, albeit that is an optimization, and the diff-sync approach would still work without that (and would not use any more API calls than the 1st/non-diff-sync approach).
Conclusion
It’s been awhile since Mark and I worked on this system, but I really enjoyed his refactoring.
I was thinking about this approach as I’d recently come across a separate system that is also basically a “vendor systems integration” problem, and so reached out to Mark to rekindle my memory of how the old Bizo system worked. And I figured I might as well write it down so I don’t forget.
If you’re implementing systems integrations, hopefully this was useful, and if you’re implementing vendor APIs, please implement codes!